
- 著者:Alex Krizhevsky, Ilya Sutskever, and Geoffrey E. Hinton.
- 出典:NeurIPS 2012
- 一行要約:ILSVRCのテストセットにてエラー率top-5 : 17.0%, top-1 : 37.5%を記録し、ILSVRC-2012にて優勝したCNNモデルの論文。
何をしたか
- 約1,200,000枚の高画質画像を1,000クラス分類するILSVRCのトレーニングセットをCNNで学習し、テストセットにてエラー率top-5 : 17.0%, top-1 : 37.5%で、従来のSoTA手法を大幅に更新。
- このCNNは60,000,000個の学習パラメータと650,000個のニューロンを含む。
- 学習高速化のために、non-saturating(不飽和?非線形のこと?)ニューロンの使用とGPUによる畳込み操作の実装。
- 過学習抑制のために、dropoutを使用。
- ILSVRC-2012の2位手法のtop-5エラー率26.2%と比べて、本モデルは大差をつけて優勝した。
何が嬉しいか
- 近年はデータセットの規模が大きなってきており、大きな変動性を持つ現実世界の物体認識のためにはそれらの大規模データセットが必要不可欠である。深さや幅を変化させられるCNNモデルは、表現力を豊かにできデータセットの規模の大きさに対応できるため有効である。
- 純粋なNNよりCNNの方がパラメータ数は少ないので学習しやすい。(しかしパラメータが少ない分理論的にはパフォーマンスは低い。←そうとう学習難しいだろうけど。)
- GPUにより、特に畳み込み操作において学習の高速化を図ることもできている。GPUの性能が上がればより大きなデータセットの学習も可能になり認識精度向上に寄与できる。
手法
1. データセット
- ImageNet
- 約1500万枚、約22,000クラスを有するデータセット。
- ImageNet Large-Scale Visual Recognition Challenge (ILSVRC)
- ImageNetのサブセットであり、1,000クラスそれぞれ約1,000枚の画像で構成されたデータセット。
- 学習データ : 約120万枚、検証用データ : 5万枚、テストデータ : 15万枚。
- 一般的になされる前処理である同比率で短い辺を256[px]としてリサイズし、中央の224x224[px]をクロップした。
- 各ピクセルに各RGBチャネルの平均を除算する以外の他の前処理は行わなかった。
2. モデルのアーキテクチャ
2.1 ReLU Nonlinearity (非線形の活性化関数)
- 非線形の活性化関数にReLUを使用することで、よく使用されるsigmoidやtanhより高速な学習の収束に至った。
- 以下の図はReLU(solid)とtanh(dash)のCIFAR-10での学習曲線の比較。
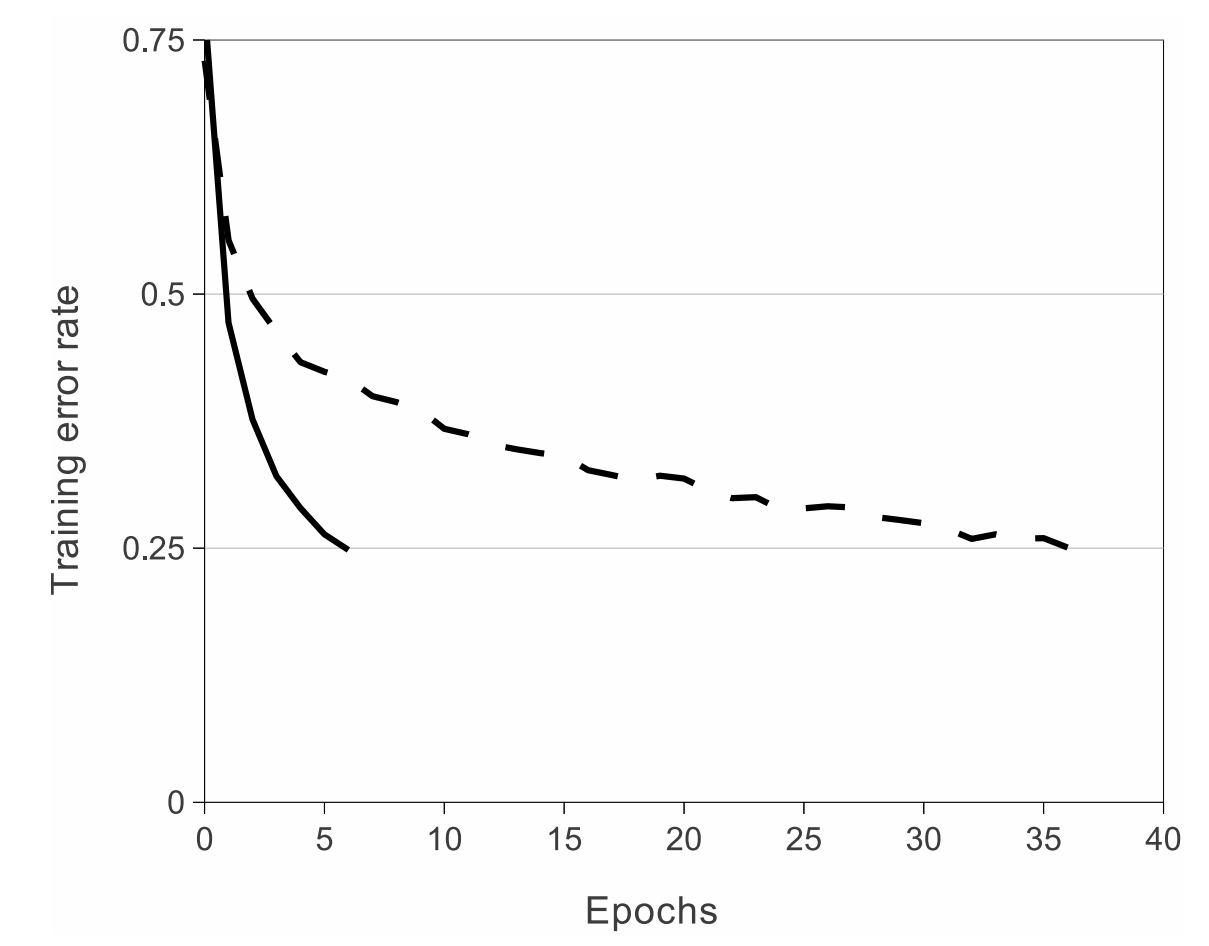
- CIFAR-10で学習エラー率が25%になるまで、ReLUはtanhと比べて6倍早かった。
2.2 Training on Multiple GPUs
- マルチGPUで学習カーネルを2つのGPUにわけることで高速な演算を可能にした。
- マルチGPUにより、top-1, top-5エラー率をそれぞれ1.7%, 1.2%低くすることができた。
2.3 Local Response Normalization (局所応答正規化, LRN)
- 本来ReLUがあれば正規化の必要は無いが、LRNが一般化を補助してくれる。
- 次式で表される正規化であり、カーネルにおける位置に適応したReLU後の出力を、正規化後の出力をで表す。 \begin{align} b_{xy}^i = \frac{a_{xy}^i}{\displaystyle\left (k+\alpha\sum_{j=\max(0,i-n/2)}^{\min(N-1,i+n/2)}(a_{xy}^j)^{2}\right)^{\beta}} \end{align}
- はカーネルの総数、はハイパーパラメータでそれぞれを使用した。
- LRNにより、top-1, top-5エラー率をそれぞれ1.4%, 1.2%低くすることができた。
- PyTorchの実装は以下の通り。
# Code from https://github.com/pytorch/pytorch/blob/master/torch/nn/functional.py#L2342
def local_response_norm(input: Tensor, size: int, alpha: float = 1e-4, beta: float = 0.75, k: float = 1.0) -> Tensor:
r"""Applies local response normalization over an input signal composed of
several input planes, where channels occupy the second dimension.
Applies normalization across channels.
See :class:`~torch.nn.LocalResponseNorm` for details.
"""
if has_torch_function_unary(input):
return handle_torch_function(local_response_norm, (input,), input, size, alpha=alpha, beta=beta, k=k)
dim = input.dim()
if dim < 3:
raise ValueError(
"Expected 3D or higher dimensionality \
input (got {} dimensions)".format(
dim
)
)
div = input.mul(input).unsqueeze(1)
if dim == 3:
div = pad(div, (0, 0, size // 2, (size - 1) // 2))
div = avg_pool2d(div, (size, 1), stride=1).squeeze(1)
else:
sizes = input.size()
div = div.view(sizes[0], 1, sizes[1], sizes[2], -1)
div = pad(div, (0, 0, 0, 0, size // 2, (size - 1) // 2))
div = avg_pool3d(div, (size, 1, 1), stride=1).squeeze(1)
div = div.view(sizes)
div = div.mul(alpha).add(k).pow(beta)
return input / div- (channel-wiseの指定したカーネルサイズ内の正規化なのかな。最近の手法ではあまり見ない。)
2.4 Overlapping Pooling (重複プーリング)
- プーリングの際にプーリングのカーネルサイズよりカーネルのストライドを小さくすることで、重複プーリングが実現できる。
- カーネルサイズ=3、カーネルのストライド=2にすることで、top-1, top-5エラー率をそれぞれ0.4%, 0.3%低くすることができた。
2.5 Overall Architecture (アーキテクチャの概要)
- 畳み込み層 × 5
- いくつかの畳み込み層の後にmax-pooling層
- 全結合層 × 3
- 最後に1,000出力のsoftmaxを施す。
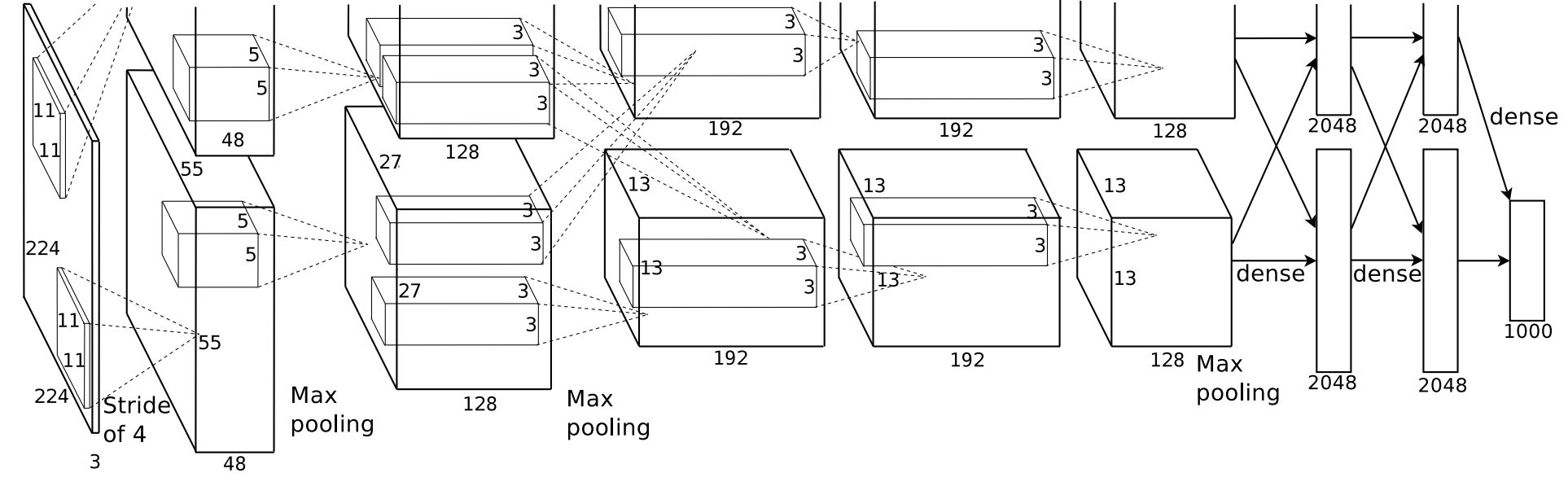
3. 過学習抑制
3.1 データ水増し
- データの形状を変化させることによってデータ水増しを図り、生成にはGPUではなくCPUを用いた。
- 1つ目の形状変化は、クロップと左右反転。
- 学習時には256x256の画像を224x224のパッチにランダムクロップ + 左右反転を行う。
- テスト時には256x256の画像を(右上、右下、左上、左下、中央) x 左右反転の合計10枚を評価し、softmaxの出力を平均して最終的な結果を出す。
- 2つ目の形状変化は、画像のRGBチャネルの強度変化。
- RGB画像に対して以下を加算する。 \begin{align} [\bf p_{1}, \bf p_{2}, \bf p_{3}][\alpha_{1}\lambda_{1}, \alpha_{2}\lambda_{2}, \alpha_{3}\lambda_{3}]^\it T \end{align}
- はRGB画素値の3×3共分散行列の番目の固有ベクトルと固有値を表す。はと表記して良いのかな…?
3.2 Dropout
- 学習の際に50%の確率でニューロンの出力を0にしてランダムにニューロンの学習を切り離すことで、擬似的にCNNの異なるアーキテクチャのアンサンブルとなり過学習を抑制。
- テストの際はdropoutは行わないが、出力に0.5をかける。
4. 学習の詳細
- オプティマイザとして、Momentum SGDを使用。
- バッチサイズ : 128、モーメンタム : 0.9、荷重減衰, weight decay : 0.0005で以下の式で学習パラメータを更新する。
\begin{align} v_{i+1} &\leftarrow 0.9\cdot v_{i} - 0.0005 \cdot \epsilon \cdot w_{i} - \epsilon \cdot \left \langle \frac{\partial L}{\partial w} \mid_{w_{i}} \right \rangle_{D_{i}} \\\ w_{i+1} &\leftarrow w_{i} + v_{i+1} \end{align}
- はイテレーション、は学習率、はモーメント変数、はバッチの勾配の平均。
実験
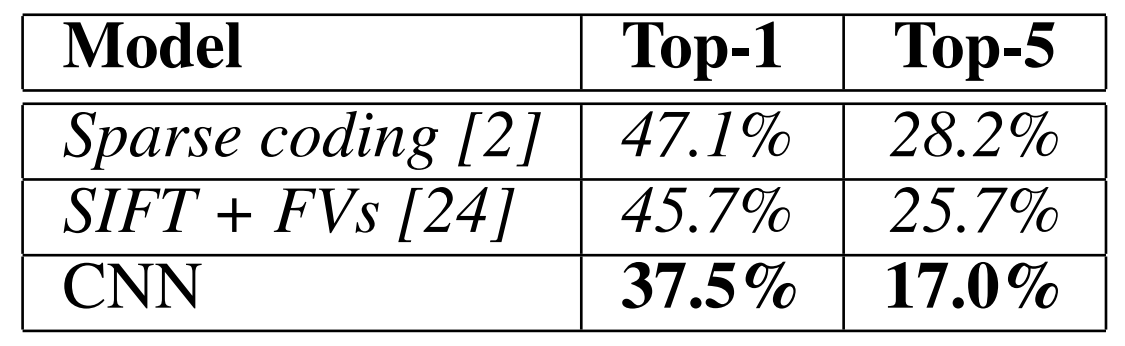
- ILSVRC-2010のテストセットでの比較
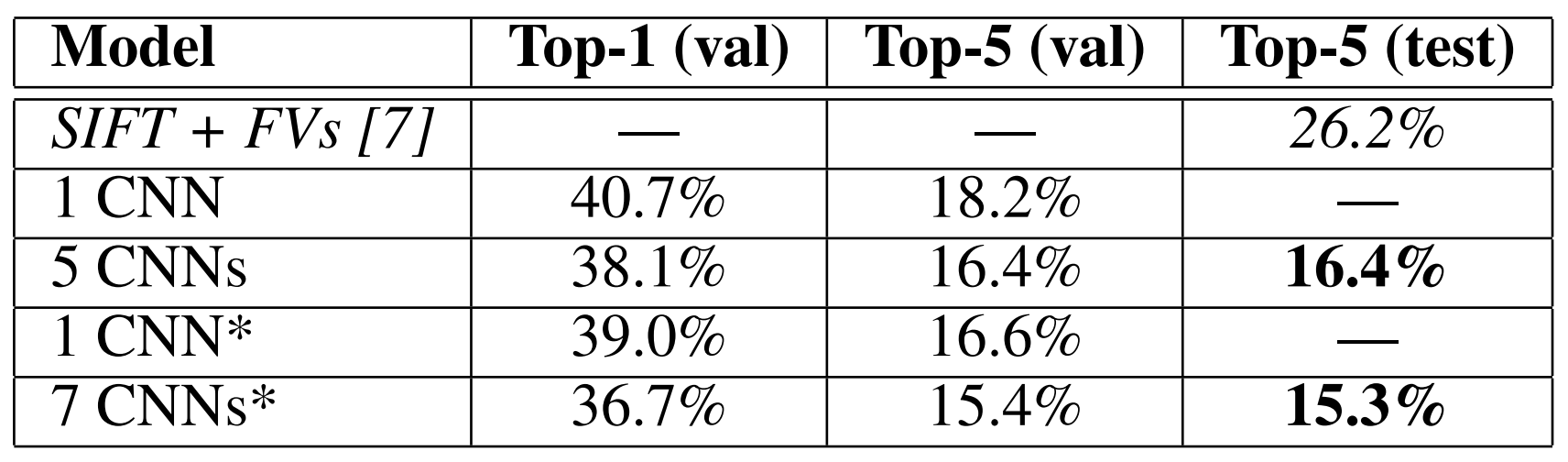
- ILSVRC-2012のテストセットでの比較
- 定性的な評価

議論
- LRNとデータ水増しのRGB強度の変更は現在はどのくらい使われるのだろうか。
- 2012年の論文と思うと、現在のCNNの概形と比較するとこの時期にはほぼ完成されている気がする。
次に読むべき論文
- VGG : Very Deep Convolutional Networks for Large-Scale Image Recognition paper link
Reference
- Alex Krizhevsky, Ilya Sutskever, and Geoffrey E. Hinton. “Imagenet classification with deep convolutional neural networks.” Advances in neural information processing systems 25 (2012): 1097-1105. paper link