
Deep Residual Learning for Image Recognition
- 表題 : Deep Residual Rearning for Image Recognition.
- 著者 : Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun
- 出典 : CVPR 2016
- 一行要約 : CNNに残差学習を取り入れる事で勾配消失(Degradation)の問題に対処でき、ILSVRCのテストセットにてエラー率top-5 : 3.57%を記録し、ILSVRC-2015にて優勝したCNNモデルの論文。
何をしたか
- 残差学習をCNNに取り入れる事で、既存のモデルよりもより深いモデルを容易に最適化した。
- 残差学習の有無とモデルの深さに対して包括的な実験を行った。
- ILSVRC-2015画像分類タスクにてTop-5エラー率3.57%で優勝した。
- COCO物体検出タスク、ImageNet物体特定タスクなどにおいても優勝した。
何がうれしいか
- 残差学習は、恒等写像により学習する写像に加算させる事によって、学習パラメータを増やすことなく用意に実装できる。
- 残差学習によって勾配消失問題に対処できることにより、非常に深いモデルをSGDで容易に最適化可能になる。
- モデルの計算量増加を抑え、非常に深く、認識精度の高いモデルを実現できる。
手法
Residual Learning (残差学習)
- 複数の積み重ねたレイヤの写像を $ \mathcal{H} ( \mathbf{x} ) $ とする。 ($ \mathbf{x} $ はレイヤの最初の入力を示す。)
- ここで残差学習は $\mathcal{F} ( \mathbf{x} ) := \mathcal{H} ( \mathbf{x} ) - \mathbf{x}$ を近似することを表す。
- 従って元の学習対象の写像は $ \mathcal{H} ( \mathbf{x} ) = \mathcal{F} ( \mathbf{x} ) + \mathbf{x} $ となる。
- もし、恒等写像が最適である場合は学習対象の写像(solver)の重みを0に近づける事で学習ができる。
- 実際には恒等写像が最適である可能性が低いが、実際の挙動を見ると学習対象の写像のみを学習させるよりも恒等写像を参照とした学習対象の写像の学習はより簡単になる。
- 直接レイヤの応答(Response)を見ると恒等写像により微細な摂動であることが確認できる。(恒等写像が学習の手助けをしてくれている。)
Identity Mapping by Shortcuts (ショートカットによる恒等写像)
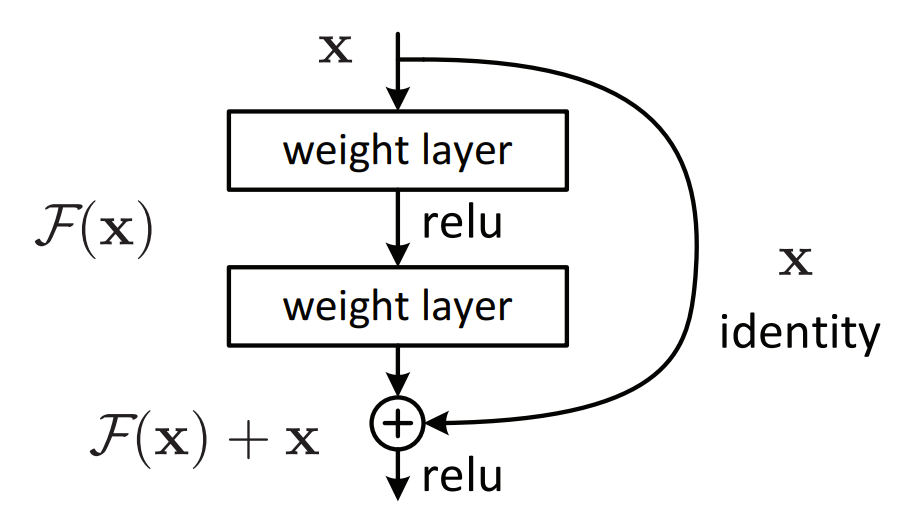
- ショートカットコネクションにより恒等写像の加算を実現し、以下の定式で与えられる。
- ここで $ \mathbf{y}, \mathbf{x} $ はそれぞれ出力、入力ベクトルを示す。
- $ \mathcal{F} ( \mathbf{x}, {W_{i}} ) $ は学習対象の写像であり、上記の図のような2つのレイヤの場合は、 $ \mathcal{F} = W_{2} \sigma ( W_{1}\mathbf{x} ) $ となる。
-
$ \sigma $ は活性化関数ReLUを示す。
- 恒等写像を加算する際にベクトルの次元を合わせる必要があるため、もし次元が一致しない場合は以下の定式を学習する。
- ここで $ W_{s} $ は次元調整に使用されるレイヤの重みである。(よくlinear proction とも呼ばれる)
Network Architecture (モデル構造)
- プレーンなモデルは VGG[1] から着想を得て設計するために、以下の2つのルールを設ける。
- ルール(1): 同じ解像度の特徴マップを出力させる層間ではチャネル数(フィルタ数)を一致させる。
- ルール(2): 解像度が1/2する場合にチャネル数(フィルタ数)を2倍にする。
-
最後にはGlobal Average Pooling、全結合 w/ softmax層、を通してマルチクラス分類を行う。
- 以下にVGG-19とプレーンモデル34とResNet34の比較を示す。
| VGG-19 | 34-layer plain | 34-layer residual |
|---|---|---|
| 3x3 conv, 64 | ↓ | ↓ |
| 3x3 conv, 64 | ↓ | ↓ |
| pool, 1/2 | ↓ | ↓ |
| 3x3 conv, 128 | ↓ | ↓ |
| 3x3 conv, 128 | 7x7 conv, 64, 1/2 | 7x7 conv, 64, 1/2 |
| pool, 1/2 | pool, 1/2 | pool, 1/2 |
| 3x3 conv, 256 | 3x3 conv, 64 | 3x3 conv, 64 |
| 3x3 conv, 256 | 3x3 conv, 64 | 3x3 conv, 64, add shortcut |
| 3x3 conv, 256 | 3x3 conv, 64 | 3x3 conv, 64 |
| 3x3 conv, 256 | 3x3 conv, 64 | 3x3 conv, 64, add shortcut |
| ↓ | 3x3 conv, 64 | 3x3 conv, 64 |
| ↓ | 3x3 conv, 64 | 3x3 conv, 64, add shortcut |
| pool, 1/2 | 3x3 conv, 128, /2 | 3x3 conv, 128, /2 |
| 3x3 conv, 512 | 3x3 conv, 128 | 3x3 conv, 128, add shortcut w/ down channels |
| 3x3 conv, 512 | 3x3 conv, 128 | 3x3 conv, 128 |
| 3x3 conv, 512 | 3x3 conv, 128 | 3x3 conv, 128, add shortcut |
| 3x3 conv, 512 | 3x3 conv, 128 | 3x3 conv, 128 |
| ↓ | 3x3 conv, 128 | 3x3 conv, 128, add shortcut |
| ↓ | 3x3 conv, 128 | 3x3 conv, 128 |
| ↓ | 3x3 conv, 128 | 3x3 conv, 128, add shortcut |
| pool, 1/2 | 3x3 conv, 256, /2 | 3x3 conv, 256, /2 |
| 3x3 conv, 512 | 3x3 conv, 256 | 3x3 conv, 256, add shortcut w/ down channels |
| 3x3 conv, 512 | 3x3 conv, 256 | 3x3 conv, 256 |
| 3x3 conv, 512 | 3x3 conv, 256 | 3x3 conv, 256, add shortcut |
| 3x3 conv, 512 | 3x3 conv, 256 | 3x3 conv, 256 |
| ↓ | 3x3 conv, 256 | 3x3 conv, 256, add shortcut |
| ↓ | 3x3 conv, 256 | 3x3 conv, 256 |
| ↓ | 3x3 conv, 256 | 3x3 conv, 256, add shortcut |
| ↓ | 3x3 conv, 256 | 3x3 conv, 256 |
| ↓ | 3x3 conv, 256 | 3x3 conv, 256, add shortcut |
| ↓ | 3x3 conv, 256 | 3x3 conv, 256 |
| ↓ | 3x3 conv, 256 | 3x3 conv, 256, add shortcut |
| pool, 1/2 | 3x3 conv, 512, /2 | 3x3 conv, 512, /2 |
| ↓ | 3x3 conv, 512 | 3x3 conv, 512, add shortcut w/ down channels |
| ↓ | 3x3 conv, 512 | 3x3 conv, 512 |
| ↓ | 3x3 conv, 512 | 3x3 conv, 512, add shortcut |
| ↓ | 3x3 conv, 512 | 3x3 conv, 512 |
| ↓ | 3x3 conv, 512 | 3x3 conv, 512, add shortcut |
| classifer | classifer | classifer |
Implementation (実装)
- データ水増しは AlexNet [2], VGG [1] を参照。
- Batch Normalization を畳み込み層と活性化関数層の間に挟む。
- moemntum SGD を使用し、validationのエラー率が停滞したら学習率を1/10する。
- 分類層にはdropoutなし。
- テスト時には10クロップ入力し、平均をとる。
実験
議論
次に読むべき論文
Reference
-
He, Kaiming, et al. “Deep residual learning for image recognition.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2016. paper link
-
[1] Simonyan, Karen, and Andrew Zisserman. “Very deep convolutional networks for large-scale image recognition.” arXiv preprint arXiv:1409.1556 (2014). paper link
-
[2] Alex Krizhevsky, Ilya Sutskever, and Geoffrey E. Hinton. “Imagenet classification with deep convolutional neural networks.” Advances in neural information processing systems 25 (2012): 1097-1105. paper link